日處理20億數據 實時用戶行為服務系統架構實踐
在大數據時代,處理海量用戶行為數據并實現實時分析已成為企業提升用戶體驗和業務決策的關鍵。本文將介紹一個日處理20億條數據的實時用戶行為服務系統架構實踐,涵蓋數據采集、傳輸、存儲、計算及可視化等核心環節。
一、系統架構概述
該實時用戶行為服務系統采用分層架構設計,主要包括數據采集層、數據傳輸層、數據處理層、數據存儲層和應用服務層。系統通過分布式技術保證高可用性和可擴展性,確保在數據量激增時仍能穩定運行。
二、數據采集層
數據采集層負責從各類客戶端(如Web、App、小程序等)收集用戶行為數據。采用輕量級SDK嵌入客戶端,通過異步方式上報事件數據,避免阻塞用戶操作。同時,支持多種數據格式(如JSON、Avro),并利用數據壓縮和批量上傳策略減少網絡開銷。日均采集數據量達20億條,峰值QPS超過50萬。
三、數據傳輸層
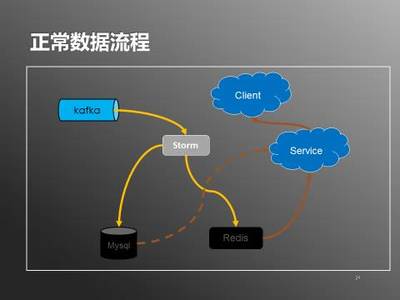
數據傳輸層使用高吞吐量的消息隊列(如Kafka)作為數據管道,確保數據可靠、有序地傳遞。Kafka集群采用多副本機制,防止數據丟失,并通過分區策略實現負載均衡。數據在此層進行初步過濾和格式標準化,為后續處理做好準備。
四、數據處理層
數據處理層是系統的核心,采用流處理框架(如Apache Flink)進行實時計算。Flink作業消費Kafka中的數據,執行用戶行為分析、聚合、去重等操作,并支持復雜事件處理(CEP)以識別特定模式。計算結果實時寫入存儲層,同時將指標數據推送至監控系統,便于運維人員實時追蹤系統狀態。
五、數據存儲層
數據存儲層分為實時存儲和歷史存儲兩部分。實時數據存儲使用OLAP數據庫(如ClickHouse)或時序數據庫(如InfluxDB),支持低延遲查詢和多維分析;歷史數據則存入數據倉庫(如Hadoop HDFS)或云存儲,用于離線分析和模型訓練。通過數據生命周期管理,自動遷移冷數據,優化存儲成本。
六、應用服務層
應用服務層通過API網關對外提供數據服務,支持實時查詢、儀表盤展示和告警功能。前端應用(如數據大屏、報表系統)通過RESTful API或WebSocket獲取數據,并以圖表形式直觀呈現用戶行為趨勢。系統集成機器學習平臺,實現個性化推薦和異常檢測等高級功能。
七、監控與運維
為保障系統穩定性,我們建立了全面的監控體系,包括資源監控(CPU、內存、網絡)、業務指標監控(處理延遲、數據準確性)和日志追蹤。采用容器化部署(如Kubernetes)和自動化運維工具,實現快速擴縮容和故障自愈。
八、實踐經驗與優化
在實踐中,我們面臨了數據傾斜、網絡延遲和資源爭用等挑戰。通過優化數據分區策略、引入緩存機制和調整計算邏輯,系統性能得到顯著提升。未來,我們將探索邊緣計算和AI驅動的自動化運維,以應對更大規模的數據處理需求。
該實時用戶行為服務系統通過分層架構和先進技術棧,實現了日均20億數據的高效處理與實時分析,為企業業務增長提供了堅實的數據支撐。隨著技術的演進,系統將持續優化,以滿足日益復雜的業務場景。
如若轉載,請注明出處:http://m.vlij.cn/product/2.html
更新時間:2026-03-19 13:18:56









